
Importance of Data Quality
The importance of data quality cannot be overlooked in today’s data-driven world. Organizations are increasingly leveraging data to gain a competitive advantage, but poor IT asset data quality can lead to inaccurate insights, security vulnerabilities, and compliance risks.
We are in the era of Big Data, where the sheer volume, variety, and velocity of data have surpassed the capabilities of traditional manual analysis and even conventional databases. This has created a growing demand for advanced data processing and analytics. Fortunately, improvements in computing power and the development of sophisticated algorithms now enable organizations to integrate and analyze complex datasets more effectively.
With cybersecurity threats evolving rapidly, high-quality data is essential for detecting anomalies, identifying threats, and making informed decisions. Companies that prioritize data accuracy, consistency, and security can enhance their cyber defenses, ensuring they stay ahead of potential risks. The importance of data quality becomes even more evident when considering its role in security automation, where real-time responses depend on accurate, up-to-date information.
Why is Data Quality Important?
Accurate data is the foundation of cybersecurity decision-making. Without data quality, organizations risk making security assessments based on incomplete or misleading information. The importance of data quality extends beyond just cybersecurity, it impacts regulatory compliance, risk management, and overall business intelligence.
For instance, false positives in cybersecurity alerts can overwhelm security teams, leading to alert fatigue. On the other hand, false negatives, where real threats go undetected, can result in severe security breaches. The importance of data quality in threat intelligence ensures that cybersecurity teams receive precise, actionable alerts rather than being flooded with irrelevant or incorrect information.
Machine Learning and Artificial Intelligence
Machine Learning (ML) and Artificial Intelligence (AI) are now essential components of modern technology, shaping industries and everyday life. A 2020 Deloitte survey revealed that 67% of companies were already using machine learning, while 97% were either using or planning to implement it within the next year.

The concept of Machine Learning dates back to 1959, when Arthur Samuel defined it as a sub field of Artificial Intelligence that “gives computers the ability to learn without being explicitly programmed.” Over the past 25 years, Machine Learning has become a driving force in the IT revolution, significantly impacting businesses, cybersecurity, and automation, once again highlighting the importance of data quality to fuel this transformation.
While Machine Learning originated in the late 1950s alongside early Artificial Intelligence developments, it gained momentum approximately 20 years ago with the rise of data mining, a technique that identifies patterns within vast datasets. Machine Learning builds upon this by not only detecting patterns but also adapting its behavior based on learned insights. The importance of data quality lies at the core of this process, ensuring accuracy and minimizing algorithmic bias.
Today, Machine Learning and Artificial Intelligence are transforming industries such as cybersecurity, finance, healthcare, and e-commerce, enabling advanced automation, predictive analytics, and smarter decision-making. As businesses continue integrating AI-driven solutions, understanding the potential of machine learning and artificial intelligence remains crucial for staying competitive in the digital age.
Only as Good as the Data They Learn From
Machine Learning starts with data, numbers, images, text, and more. Organizations collect vast amounts of data from diverse sources and prepare it for use as training data. The importance of data quality cannot be overstated in this process. If the training data is flawed, the resulting Artificial Intelligence models will reflect those flaws, leading to inaccurate predictions and unreliable security measures.
While Machine Learning algorithms can help companies leverage their data for improved insights and products, they also come with limitations. Poor data quality, whether due to insufficient diversity, lack of preprocessing, or errors, can lead to biased or inaccurate models. One common issue is overfitting, where an Machine Learning model becomes too closely tuned to its training data, learning patterns (including noise) that don’t generalize to new data. As a result, the model may perform exceptionally well on training data but fail when exposed to unseen real-world inputs.
To maximize the effectiveness of Machine Learning, organizations must prioritize high-quality, diverse, and well-preprocessed training data. Without it, even the most sophisticated Machine Learning models will struggle to deliver meaningful and reliable results.
Machine Learning Data Quality
The importance of data quality and diversity has become a crucial pillar in Data Science, especially in asset risk management (ARM), where even small mistakes can lead to significant security vulnerabilities. At Sepio, we prioritize data cleansing and diversification to ensure optimal performance and accuracy in our Machine Learning models and algorithms.
We recognize that the effectiveness of Machine Learning driven cybersecurity solutions depends on the quality and diversity of training data. That’s why we employ rigorous data collection strategies, leveraging advanced techniques to gather, validate, and refine data to the highest standards. Our approach includes:
- Thorough data validation to ensure accuracy and reliability.
- Rigorous data cleansing to eliminate inconsistencies and biases.
- Continuous monitoring to maintain data integrity over time.
By maintaining high-quality, diverse datasets, Sepio ensures that our AI-driven cybersecurity solutions remain robust, adaptive, and effective against evolving threats.
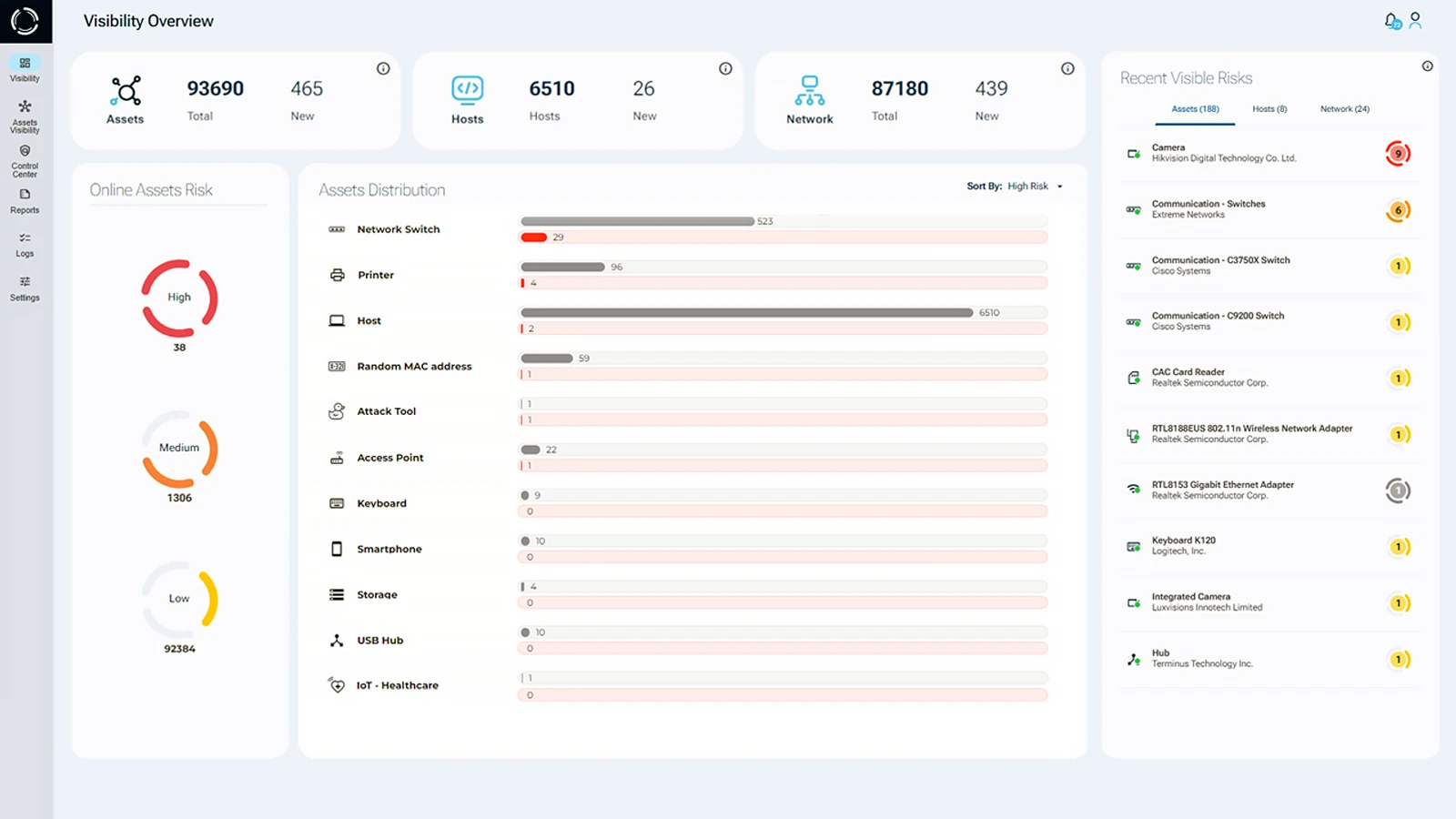
See Every Known and Shadow Asset
Talk to an expert. Discover how Sepio’s advanced cybersecurity solutions can help you take control of your asset risks. Speak with one of our experts today to learn how to enhance your security posture with cutting-edge hardware asset risk management.








